
Avaliando a Performance de um Backup

Executar um backup pode parecer uma atividade trivial. No entanto, apesar de sua aparente simplicidade, diversos fatores interconectados entram em ação durante o processo e podem impactar diretamente a performance da cópia dos dados.
Abaixo vou destacar os principais elementos e componentes que são utilizados durante ao backup:
Origem dos dados (Source)
A origem dos dados sempre vai ser o primeiro componente envolvido durante a execução de um backup. A origem pode ser um servidor, um hypervisor, um compartilhamento, uma storage, dentre outros. Os principais elementos que influenciam nessa camada são:
- Velocidade de leitura do storage
- Latência e throughput da rede
- Carga do host e impacto de snapshots
Camada de Transporte (Proxies e Data Movers)
A camada de transporte também é um componente importante para que os backups executem conforme o esperado. Existem diversos modos de transporte que pode ser utilizados durante um backup. Também existem modos de de compressão e deduplicação que influenciam na performance do backup. Não vou destacar cada um desses pontos nesse momento (ainda vou escrever um outro artigo sobre isso), porém vou destacar aqui abaixo os principais elementos quem influenciam no backup dentro da camada de tranposrte:
- Capacidade de processamento e memória RAM dos proxies
- Modo de transporte (Hotadd, NBD, Direct SAN, SMB, NFS etc.)
- Compressão e deduplicação inline
Rede (Network)
A rede com certeza é um dos pontos que mais influenciam durante o processamento de um backup. Abaixo as principais velocidades de rede do mercado:
- Rede 1 GbE
- Rede 2.5 GbE
- Rede 10 GbE
- Rede 25 GbE
- Redes 40 GbE
- Redes 100 GbE
Destino do backup (Repository / Target Storage)
O destino do backup sempre vai ser um repositório, seja ele local on premisse ou remoto na cloud. Aqui vou focar no repositório local que é o repositório adequado quando estamos buscando performance para os backups diários. Repositório em nuvem normalmente são utilizados para backups de longa retenção como é o caso dos backups semanais, mensais e anuais. De qualquer forma vou listar os principais elementos que influenciam nessa etapa:
- IOPS sustentáveis para gravação
- Tamanho de bloco e alinhamento (ex.: XFS Reflink 1MB)
- Latência média de gravação
Infraestrutura Auxiliar
Além dos 4 principais fatores que listei acima, existem alguns outros componentes que podem influenciar na performance e no comportamento do backup. Fatores esse que vão desde a camada de sistema operacional até alguma aplicação especificas como exemplo de bancos de dados, Active Directory, Microsoft 365, etc:
- Dependências de software
- VSS
- Snapshots
- Drivers
- APIs
Como Avaliar a Performance no Veeam Backup & Replication
O Veeam Backup & Replication (VBR) possui um método simples para avaliar a saúde e performance de backup. Ao analisar a estatística de um backup podemos ver o seguinte status:
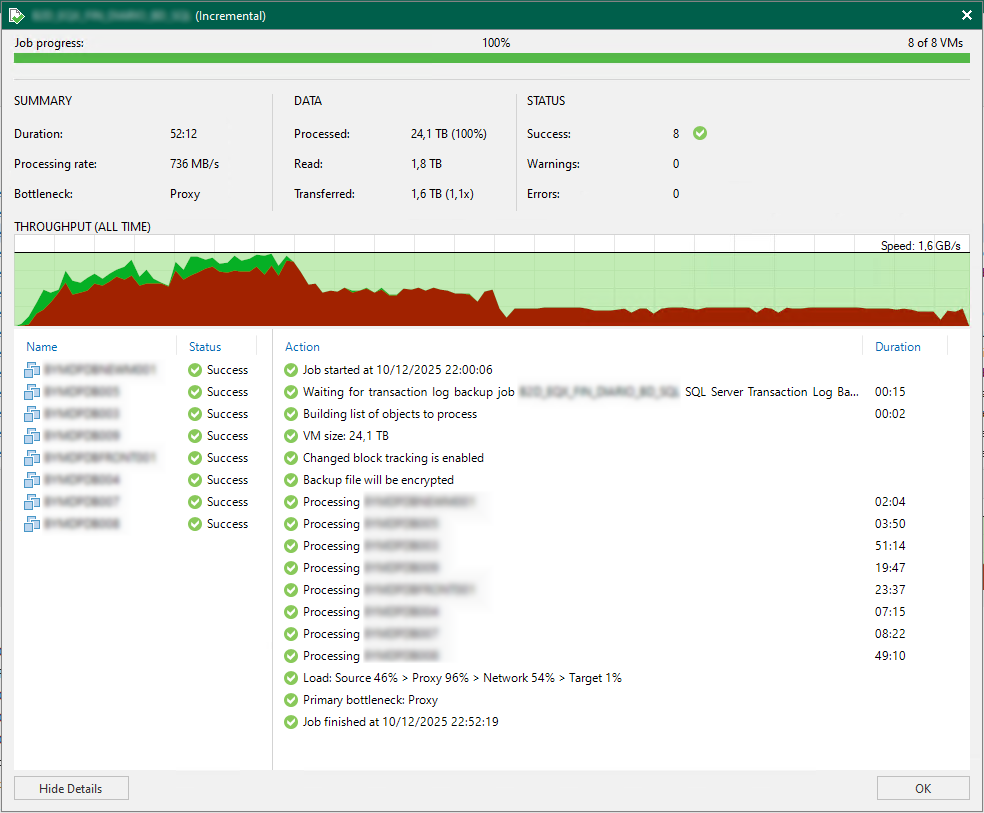
Nesse exemplo podemos ver um backup incremental de 8 máquinas virtuais. No cabeçalho temos 3 principais sessões que são o summary, data, status. Vou abordar os aspectos de cada um deles:
Summary (Resumo)
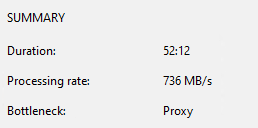
Aqui podemos ver 3 principais aspectos do backup:
- Duração – 52:12
- Taxa de Processamento – 736 MB/s
- Gargalo – Proxy
Sendo assim podemos ver o tempo que o backup levou, a velocidade media do backup e o principal gargalo.
Data (Dado)
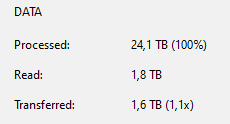
qui então temos 3 dados para avaliar:
- Dado Processado – 24.1 TB
- Dado Lido – 1.8 TB
- Transferido – 1.6 TB
O dado processado é o tamanho total dos dados das 8 VMs que mostrei acima. Isso quer dizer que as 8 maquinas virtuais possuem o tamanho total provisionado de 24 TB.
O dado lido é tamanho total do backup depois de processado. Aqui nesse caso foi um backup incremental que totalizou 1.8 TB em comparação com o dia anterior.
Já o o dado transferido é o tamanho do backup depois de deduplicado e comprimido. Nesse exemplo os 1.8 TB conseguiram ser transformado em 1.6 TB.
Sendo assim, o tamanho total do dado que foi transferido através da rede até o repositório foi de 1.6 TB.
Status
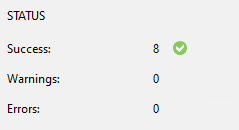
Por ultimo é possível ver um status geral do backup. Aqui podemos ver que das 8 máquinas virtuais totas elas foram processadas com sucesso. Não tivemos alertas e erros durante o backup.
Analisando o Gargalo
Outro ponto que podemos analisar mais detalhado é os detalhes do gargalo do backup. Para isso basta posicionar o mouse em cima do bottleneck:
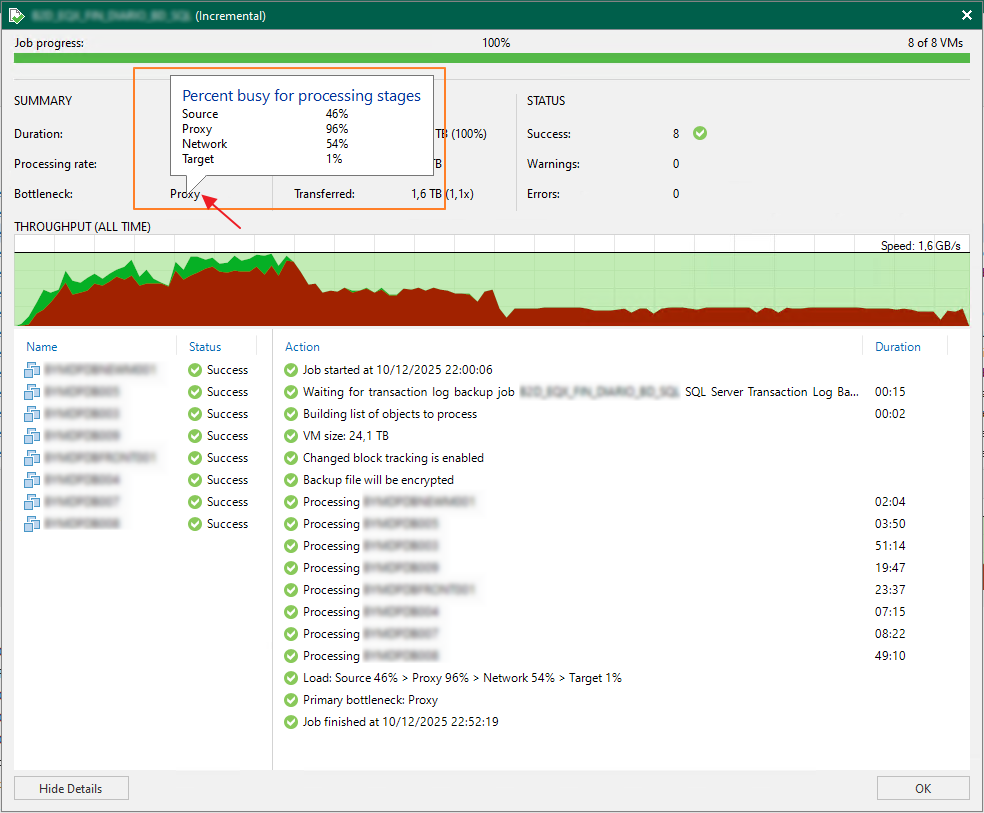
Com isso temos o seguinte aspecto:

Aqui podemos constatar que o principal gargalo durante a execução do backup foi os proxies. Isso não quer dizer que o backup executou de uma maneira ruim. Temos que lembrar que nesse exemplo foi processado um total de 1.6 TB que levou menos de 1 hora executar. Outro ponto interessante a se observar é o Target (repositório) foi o menor dos ofensores para a execução do backup.
Principais Métricas para Avaliação
Aqui vou trazer um compilado de algumas métricas e avaliações que devemos considerar:
Throughput (Taxa de Transferência)
A métrica central para avaliar performance.
Exemplo: 200 MB/s, 1,5 GB/min, 1,2 TB/h.
Interpretar throughput envolve verificar:
- Se a velocidade está alinhado às expectativas do hardware
- Se o throughput varia entre execuções do mesmo job
- Se o principal limitador é a origem ou destino
Source Bottleneck (Leitura)
Verificar se esta ocorrendo algum desses comportamentos:
- Demora para criar snapshots.
- Latência no storage de produção.
- Host com CPU alta ou datastore/storage sobrecarregado.
Target Bottleneck (Escrita)
Avaliar os seguintes aspectos:
- Repositório com discos lentos
- Alta latência (>20ms em storage mecânico, >5ms em SSD)
- XFS/ReFS
Processamento (Proxy / Data Mover)
Avaliar os seguintes comportamentos:
- CPU acima de 80%.
- Número insuficiente de streams e tarefas simultaneas
- Modo de transporte utilizado
Janela de Backup
A janela de backup é tempo hábil que o negócio permite que o backup seja executado.
Sendo assim devemos:
- Tempo planejado da janela
- Tempo real de execução
Caso os backups ultrapassem a janela permitida é um sinal que a performance deve ser otimizada.
Taxa de deduplicação e compressão
Os proxies são o principal responsável pela compressão e deduplicação do Veeam. Quanto maior esse indice, menor será o tráfego de escrita, impactando positivamente a performance do backup.
Indicadores Práticos de Performance
Vou deixar aqui em forma de checklist o resumo dos principais indicadores de performance que vimos até então:
No lado do software de backup
- Throughput médio e máximo
- Tempo total por job e por VM
- Identificação dos principais componentes que trazem lentidão no backup
- Alertas de throttling
No lado da infraestrutura
- Métricas do storage (IOPS, MB/s, latência)
- Saturação de rede
- Número de tasks de snapshot pendentes
- Saúde do repositório (discos, RAID, fragmentação, rebuild, etc.)
Benchmarks e Limites de Referência
Por ultimo ainda quero deixar um tabela comparativa
Use estes valores como base para determinar se a performance está coerente com o hardware:
| Camada | Valor Esperado |
| Storage SSD | 500–3000 MB/s leitura |
| Storage SAS RAID 10 | 150–600 MB/s |
| Rede 10GbE | 1.000–1.200 MB/s |
| Proxy 8 vCPU | 200–600 MB/s por job |
| Repositório XFS HDD RAID | 150–500 MB/s |
| Repositório SSD | 800 MB/s – 3 GB/s |
Se a taxa de alguns desses valores estiver abaixo de 40%, investigue os gargalos.
Conclusão e Resumo Completo de Avaliação
Como vimos até então existem diversas coisas que vemos levar em conta durante a execução do backup. São diversos aspectos e pontos que podem aferir o backup. Sendo assim vou deixar aqui um resumo completo das etapas de avaliação que devemos considerar:
Etapa 1: Identificar o gargalo
- Verificar logs do job.
- Checar se o bottleneck é “Source”, “Proxy” ou “Target”.
- Medir throughput em MB/s.
Etapa 2: Analisar impacto por camada
- Leitura: latência e IOPS.
- Processamento: CPU do proxy.
- Escrita: latência e velocidade do repositório.
Etapa 3: Testar isoladamente cada parte
- Fazer teste de leitura (dd, fio, storage benchmark)
- Testar rede (iperf)
- Testar escrita no repositório
Etapa 4: Ajustar parâmetros
Talvez seja necessário fazer alguns ajustes, como por exemplo:
- Alterar número de tasks paralelas.
- Usar blocos maiores no XFS.
- Melhorar modo de transporte (Network para HotAdd)
- Aumentar rede de 1GbE para 10GbE.
Etapa 5: Comparar com baseline
- Criar baseline do ambiente.
- Registrar throughput por tipo de workload
- Avaliar evolução após melhorias

Meu nome é Mateus Wolff e trabalho com TI desde 2009. Sou arquiteto de soluções de proteção de dados e tenho algumas certificações como VMCE, VCP-DCV e ITIL.
Participo do programa de reconhecimento Veeam Vanguard e sou ex membro do grupo Veeam Legends.
Também sou líder do grupo Veeam User Group Brasil.



